-
[RecSys] 4-3. Collaborative Filtering-MBCF_SVD인공지능/부스트캠프 Ai Tech 2022. 3. 11. 18:26728x90
[RecSys] 4-3. Collaborative Filtering-MBCF_SVD In [1]:from IPython.core.display import display, HTML display(HTML("<style>.container { width:90% !important; }</style>"))
협업필터링(Collaborative Filtering, CF)¶
'많은 유저들로부터 얻은 기호 정보'를 통해 유저의 관심사를 자동으로 예측하는 방법
더 많은 유저/아이템 데이터가 축적될수록 협업의 효과는 커지고 추천이 정확해질 것이란 가정에서 출발
목적 : 유저 u가 아이템 i에 부여할 평점을 예측
방법
- 주어진 데이터를 활용해 유저-아이템 행렬 생성
- 유사도 기준을 정하고, 유저 혹은 아이템 간의 유사도를 구함
- 주어진 평점과 유사도를 활용해 행렬의 비어 있는 값(아직 소비하지 않은 평점) 예측
TF-IDF와는 달리 아이템이 가진 속성을 사용하지 않고 추천을 한다.
CF 분류¶
- Neighborhood-based CF (Memory-based CF)
2. Model-based CF
* Singular Value Decomposition * Matrix Factorization(SGD, ALS, BPR) * Deep Learning- Hybrid CF
Model-based CF¶
Sparsity & Scalability Issue¶
Sparsity
- 데이터가 충분하지 않으면 추천 성능이 떨어지며
- Cold start : 데이터가 부족하거나 아예 없는 유저, 아이템의 경우는 추천이 불가능하다.
Scalability
- 유저와 아이템이 늘어날수록 정확한 예측이 가능하지만 유사도 계산량이 늘어나 시간이 오래걸리게 된다.
모델 기반 협업 필터링(Model Based Collaborative Filtering, MBCF)¶
항목 간 유사성을 단순 비교하는 것에서 벗어나 데이터에 내재한 패턴을 이용해 추천하는 CF기법
Parametric ML을 사용, 데이터의 정보가 파라미터의 형태로 모델에 압축되고 파라미터는 데이터의 패턴을 나타내며, 최적화를 통해 업데이트 된다.
vs. NBCF : 이웃기반 CF는 유저/아이템 벡터를 데이터를 통해 계산된 형태로 저장(a.k.a. Memory-based CF), Model-based CF의 경우 유저, 아이템 벡터는 모두 학습을 통해 변하는 파라미터
내가했던 프로젝트 두개가 Memory-based 모델이였던것 같다. 챗봇의 경우도 Q&A 데이터를 불러와서 실시간으로 연산하는 모델, 광고옵션 추천의 경우도 이미 계산된 옵션들에서 추천하는 모델형태였다. 이때도 cold start 문제가 있었고..
현업에서는 MF를 많이 쓰며, DL모델에 응용하는 기법이 높은 성능을 낸다.
MBCF의 장점(vs. NBCF)¶
모델 학습/서빙
- 유저-아이템 데이터는 학습에만 사용되고 학습된 모델은 압축된 형태로 저장되며, 이미 학습된 모델을 통해 추천하기 때문에 서빙 속도가 빠르다.
Sparsity / Scalability 문제 개선
- NBCF에 비해 sparse한 데이터에도 좋은 성능을 보인다.
- 사용자, 아이템 개수가 많이 늘어나도 좋은 추천 성능을 보임
Overfitting 방지
- NBCF와 비교했을 때 전체 데이터의 패턴을 학습하여 일반화된 모델이 작동
- NBCF의 경우 특정 주변 이웃의 패턴을 학습하기에 주변 이웃에 의해 크게 영향을 받을 수 있음 -> overfitting 문제
Limited Coverage 극복
- NBCF의 경우 공통의 유저/아이템을 많이 공유해야만 유사도 값이 정확해짐
- Model-based는 전체 데이터의 패턴을 학습하기에, NBCF와 같이 유사도 값이 정확하지 않은 경우가 없다.
Explicit , Implicit Feedback¶
Explicit Feedback :
- 영화 평점, 맛집 별점 등 item에 대한 user의 선호도를 직접적으로 알 수 있는 데이터
Implicit Feedback :
- 클릭 여부, 시청 여부 등 item에 대한 user의 선호도를 간접적으로 알 수 있는 데이터
- 유저-아이템 간 상호 작용이 있었다면 1(positive)을 원소로 갖는 행렬로 표현 가능, 아래의 행렬에서는 O,X로 나누었다.
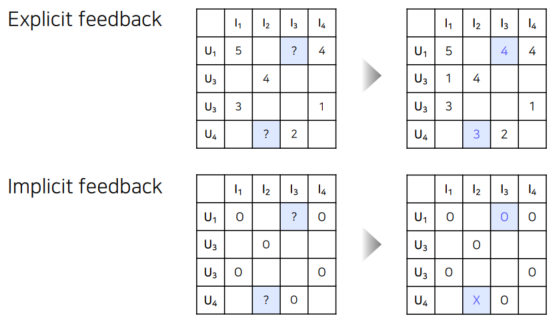
정확한 rating 값이 있는 Explicit과는 달리 Implicit은 상호작용이 있었는지, 없었는지 여부를 체크한다.
Latent Factor Model¶
embedding vactor로도 불림
유저와 아이템 관계를 잠재적 요인으로 표현할 수 있다고 보는 모델
- 유저와 아이템의 특성을 몇개의 벡터로 Dense(compact)하게 표현
유저-아이템 행렬을 저차원의 행렬로 분해하는 방식으로 작동
- 각 차원의 의미는 모델 학습을 통해 생성되어 표면적으로 알 수 없음
임베딩을 통해서 만든 유저와 아이템 벡터를 같은 (latent)벡터 공간에서 놓으면 유저와 아이템의 유사한 정도를 확인 할 수 있음
- 유저 벡터와 아이템 벡터가 유사하게 놓인다면 해당 유저에게 해당 아이템이 추천될 확률이 높음
 위의 경우는 이해를 위해서 축별로 여성,남성 등을 표시하였지만 실제로는 어떤 의미인지 알 수 없다.
위의 경우는 이해를 위해서 축별로 여성,남성 등을 표시하였지만 실제로는 어떤 의미인지 알 수 없다.
Singular Vector Decomposition(SVD)¶
Rating Matrix R에 대해 유저와 아이템의 잠재 요인을 포함할 수 있는 행렬로 분해
* 유저 잠재 요인 행렬 * 잠재 요인 대각행렬 * 아이템 잠재 요인 행렬선형 대수학의 차원 축소 기법중 하나로 분류된다.
* 주성분분석(PCA)도 차원 축소 기법 중 하나
SVD 한계점¶
분해(Decomposition)하려는 행렬의 Knowledge가 불완전할 때 정의되지 않음
- Sparsity가 높은 데이터의 경우 결측치가 많고, 실제 데잍터는 대부분 Sparse Matrix
따라서 결측된 entry를 모두 채우는 Imputation을 통해 Dense Matrix를 만들어 SVD를 수행한다.
- ex) 결측된 entry를 0 또는 유저/아이템의 평균 평점으로 채움, Imputation은 데이터의 양을 상당히 증가시키므로, 계산 비용도 높아진다.
정확하지 않은 Imputation은 데이터를 왜곡시키고 예측 성능을 떨어트린다.
- 행렬의 entry가 매우 적을 떄 SVD를 적용하면 과적합 되기 쉬운 문제
'인공지능 > 부스트캠프 Ai Tech' 카테고리의 다른 글
[L1_P_stage] 개인 회고 (0) 2022.03.12 [RecSys] 4-4. Collaborative Filtering - MBCF_MF (0) 2022.03.11 [RecSys] 4-2. Collaborative Filtering - Rating Prediction (0) 2022.03.11 [RecSys] 4-1. Collaborative Filtering (0) 2022.03.11 [RecSys] 3-2. 추천 시스템 Basic - TF-IDF (0) 2022.03.11