-
[토크ON세미나/ 추천시스템 분석 입문하기] 2강 - 추천시스템의 이해인공지능/RecSys(추천시스템) 2021. 12. 23. 16:02728x90
이 포스트는 토크ON세미나의 추천시스템 분석 입문하기(김현우 님)의 강의를 듣고 정리한 포스트입니다.
2. 컨텐츠 기반 모델
컨텐츠 기반 추천시스템은 사용자가 이전에 구매한 상품중에서 좋아하는 상품들과 유사한 상품들을 추천하는 방법이다.
- Represented Items : Items(상품 등)을 벡터 형태로 표현. 도메인에 따라 다른 방법으로 적용된다.
Represented Items으로 벡터 형태로 변환해 벡터들간에 유사도를 계산하여 유사한 Items을 찾아낸다.
2-1. 유사도 함수
유사도를 측정하는 함수들은 다양하며, 상황마다 다르게 사용된다.
2-1-1. 유클리디안 유사도
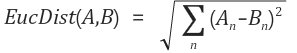
벡터 A와 B의 유클리디안 유사도 가장 직관적인 유사도 함수, 벡터간의 좌표평면상의 거리를 측정하여 가까운 순으로 유사하다고 판단
장점
- 계산하기 쉬움, 벡터의 크기가 중요한 경우 좋다
단점
- 벡터 간의 분포가 다르거나 범위가 다른 경우에는 상관성을 놓친다.
2-1-2. 코사인 유사도
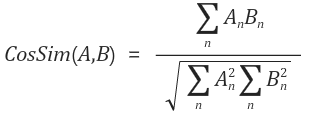
벡터 A와 B의 코사인 유사도 두 벡터를 단위벡터화 시킨뒤 내적하여 계산한다.
장점
- 벡터의 크기가 중요하지 않은 경우, 거리를 측정하기 위한 메트릭으로 사용
ex) 문서내에서 단어의 빈도수 - 문서들의 길이가 고르지 않더라도 문서내에서 얼마나 나왔는지의 비율을 확인하기에 상관 없음
단점
- 벡터의 크기가 중요한 경우에 대해서 잘 작동하지 않음
유클리디안 유사도 vs 코사인 유사도

유클리디안 - 가장 가까운 거리의 벡터를 찾는다. 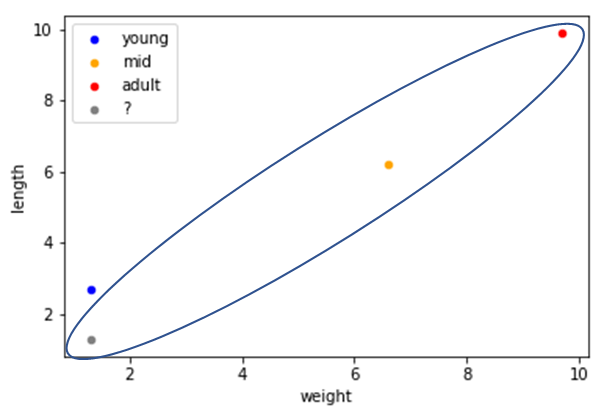
코사인유사도 - 각도가 가장 비슷한 벡터를 찾는다. 2-1-4. 그 외의 유사도
피어슨 유사도(Pearson Similarity)
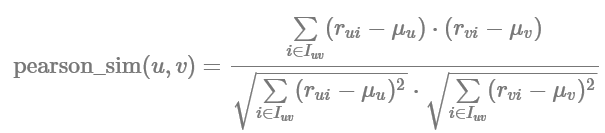
피어슨 유사도 두 벡터의 상관계수를 의미한다. 유사도가 가종 높은 경우는 값이 1, 가장 낮은 경우는 -1의 값(역 상관관계)을 가진다. ex) 특정인물의 점수기준이 극단적으로 너무 낮거나 높을 경우, 유사도에 영향을 크게 주기때문에 이를 막기 위한 유사도
자카드 유사도(Jaccard similarity)
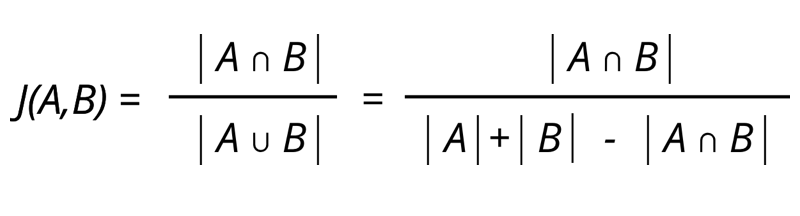
자카드 유사도 두 벡터를 각각 단어의 집합으로 만든 뒤, 두 집합을 통해 유사도를 측정하는 방식이다.
그외
Sorensen , soergel, lorentzian, Canberra, WaveHedeges, Motyka, Kulczynski, Ruzicka , Dice , hellinger, Sq-cohrd, Sq-kai, Divergence, Clark, Topsoe, Jensen-Diff 유사도 등이 존재한다.
유사도 함수의 활용법?
- 상황에 따라 적절한 유사도 함수 사용 ex) 고객 그룹마다 다른 (유사도,추천)모델을 사용한다.
- 여러 유사도 matrix를 두고 가중치를 두어 혼용하여 사용한다.
2-2. TF-IDF
TF-IDF는 특정 문서 내에 얼마나 자주 등장하는지를 의미하는 단어 빈도(TF)와 전체 문서에서 특정 단어가 얼마나 자주 등장하는지를 의미하는 역문서 빈도(DF)를 통해 "다른 문서에서는 등장하지는 않지만 특정 문서에서만 자주 등장하는 단어"를 찾아 문서 내 단어의 가중치를 계산하는 방법이다.
용도 : 문서의 핵심어 추출, 문서들 사이의 유사도 계산, 검색 결과의 중요도를 정하는 작업 등
- TF(d, t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수
- DF(t) : 특정 단어 t가 등장한 문서의 수
- IDF(d, t) : DF(t)에 반비례하는 수
- TF(d, t) * IDF(d, t) = TF-IDF(d, t)
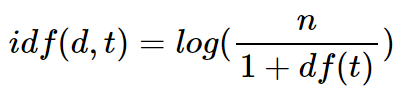
출처 :https://wikidocs.net/31698, SW마다 정의하는 방식이 다름 값이 다를 수 있다. TF-IDF를 사용하는 이유
- Item이라는 컨텐츠를 벡터로 "Feature Extract" 과정을 수행해준다.
- Counter Vectorizer : 빈도수를 기반으로 많이 나오는 중요한 단어들을 잡아준다. 다만 많이 나오는 단어라고 다 중요한 것은 아니다. ex) 조사, 관사처럼 의미가 없지만 문장에 많이 등장
- 조사와 관사와 같이 여러 문서에서 나오지만 의미가 없는 단어들에는 패널티를 줘서 적절하게 중요한 단어만 잡아내는것이 TF-IDF 기법
장점
- 직관적인 해석이 가능함
단점
- 대규모 말뭉치를 다룰 때 메모리상의 문제가 발생 : 높은 차원을 가지고, 매우 sparse한 형태의 데이터
Counter Vectorizer
docs = [ '먹고 싶은 사과', # 문서0 '먹고 싶은 바나나', # 문서1 '길고 노란 바나나 바나나', # 문서2 '저는 과일이 좋아요' # 문서3 ]from sklearn.feature_extraction.text import CountVectorizer vect = CountVectorizer() # Counter Vectorizer 객체 생성 , TF까지의 과정을 거친 상태 # 문장을 Counter Vectorizer 형태로 변형 countvect = vect.fit_transform(docs) countvect # 4x9 : 4개의 문서에 9개의 단어 , sparse matrix # toarray()를 통해서 문장이 Vector 형태의 값을 얻을 수 있음 # 하지만, 각 인덱스와 컬럼이 무엇을 의미하는지에 대해서는 알 수가 없음 countvect.toarray()
vect.vocabulary_ # dict 형태로 key는 items, values는 index 값 sorted(vect.vocabulary_) # values 값을 기준으로 정렬 import pandas as pd countvect_df = pd.DataFrame(countvect.toarray(), columns = sorted(vect.vocabulary_)) countvect_df.index = ['문서1', '문서2', '문서3', '문서4'] countvect_df # sparse matrix를 dataframe 형태로 변환해 columns을 붙여준다.
# 위의 Data Frame 형태의 coisne 유사도를 계산 from sklearn.metrics.pairwise import cosine_similarity cosine_similarity(countvect_df, countvect_df)
0번 문서와 1번 문서가 , 1번과 2번 문서가 유사하다는 결론을 얻을 수 있다. 다만 counter vectorizer는 의미없이 많이 나오는 단어도 중요하다고 보는 단점이 있다.
TF-IDF
# Counter Vectorizer -> TFidfVectorizer from sklearn.feature_extraction.text import TfidfVectorizer vect = TfidfVectorizer() tfvect = vect.fit(docs) tfidv_df = pd.DataFrame(tfvect.transform(docs).toarray(), columns = sorted(vect.vocabulary_)) tfidv_df.index = ['문서1', '문서2', '문서3', '문서4'] from sklearn.metrics.pairwise import cosine_similarity cosine_similarity(tfidv_df, tfidv_df) # TF-IDF cosine similarity
from sklearn.feature_extraction.text import TfidfVectorizer vect = TfidfVectorizer(max_features=4) tfvect = vect.fit(docs) tfidv_df = pd.DataFrame(tfvect.transform(docs).toarray(), columns = sorted(vect.vocabulary_)) tfidv_df.index = ['문서1', '문서2', '문서3', '문서4'] tfidv_df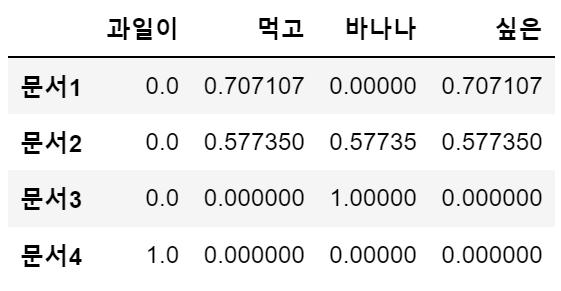
'인공지능 > RecSys(추천시스템)' 카테고리의 다른 글
[토크ON세미나/ 추천시스템 분석 입문하기] 1강 - 추천시스템의 이해 (0) 2021.12.16