-
[토크ON세미나/ 추천시스템 분석 입문하기] 1강 - 추천시스템의 이해인공지능/RecSys(추천시스템) 2021. 12. 16. 10:13728x90
이 포스트는 토크ON세미나의 추천시스템 분석 입문하기(김현우 님)의 강의를 듣고 정리한 포스트입니다.
1. 추천 시스템의 이해
1-1. 추천시스템의 개요
정의
추천시스템은 사용자(user)에게 상품(item)을 제안하는 소프트웨어 도구이자 기술
목표
어떤 사용자에게 어떤 상품을 어떻게 추천할지에 대해 이해하는것
1-2. 추천시스템의 역사
- Apriori 알고리즘(2005~2010)
- 연관상품추천
- 협업 필터링(collaborative filtering, 2010~2015)
- SVD, 넷플릭스 추천대회
- Spark를 이용한 빅데이터(2013~2017)
- FP-Growth
- Matrix Factorization
- 딥러닝을 이용한 추천시스템(2015~2017)
- 협업필터링 + 딥러닝
- Item2Vec, Doc2Vec
- Youtube Recommendation
- Wide & Deep Model
- 개인화 추천 시스템(2017~)
- Factorization Machine
- Hierarchical RNN
- 강화학습 + Re-Ranking
- 딥러닝
1-3. 연관분석(Association Analysis)
정의
룰기반의 모델, 상품과 상품 사이에 어떤 연관이 있는지 찾아내는 알고리즘, 컨텐츠 기반 추천(contents-based recommendation)의 기본이 되는 방법론이기도 하다. 어떤 상품들이 한 장바구니 안에 담기는지 살피는 모습과 비슷하여 장바구니 분석이라고도 표현함
- 연관의 정의
- 얼마나(frequent) 같이 구매가 되는가?
- A아이템을 구매하는 사람이 B아이템도 구매하는가?
예시
월마트에서 맥주 구매시 기저귀를 같이 구매하는 성향, 아이패드를 샀을때 애플펜슬을 같이 구매하는 경우
규칙평가지표
상품과 상품사이에 연관을 짓기 위해서는 선후관계도 고려를 해봐야한다. 예를들어 '달걀을 사고 라면을 산다면 참치와 햄을 산다.' 경우라는 조건이 존재한다. 이때 달걀을 사고 라면을 산다면은 조건절(Antecedent), 참치와 햄을 산다는 결과절(Consequent)이다. 이와 같은 아이템들을 구성하는 집합을 아이템 집합(Item set)이라고 한다.
여기서 조건절의 아이템 집합(달걀, 라면)과 결과절(참치, 햄)은 말 그대로 집합으로 아이템 개수는 상관 없지만, 상호배반(mutually exclusive)이어야 한다. 조건절과 결과절에 같은 아이템이 포함되어서는 안된다는 뜻이다.
규칙평가지표 - 지지도(Support)
지지도는 '조건절(A)이 일어날 확률'로 정의된다.
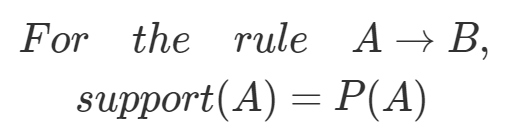
출처 : https://ratsgo.github.io/ 규칙평가지표 - 신뢰도(Confidence)
아이템 집합 간의 연관성 강도를 측정하는데 쓰는 신뢰도는 아래와 같이 조건절(A)이 주어졌을 때, 결과절(B)가 일어날 조건부확률로 정의된다.
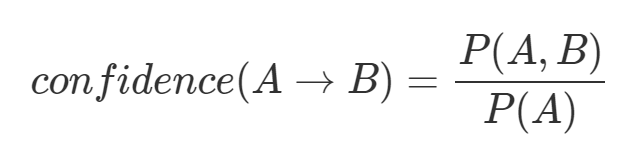
출처 : https://ratsgo.github.io/ 규칙평가지표 - 향상도(left)
향상도는 생성된 규칙이 실제 효용가치가 있는지를 판별하는데 사용된다. 조건절과 결과절이 서로 독립일 때와 비교해 두 사건이 동시에 얼마나 발생하는지 비율로 나타낸다. 향상도가 1이라면 조건절과 결과절은 서로 독립이며 규칙 사이에 유의미한 연관성이 없다는 뜻이다. 다만 향상도가 2라면 두 사건이 독립이라고 가정 하였을 때 대비 2배로 긍정적인 연관관계를 나타낸다.

출처 : https://ratsgo.github.io/ 코드에서 사용할 하이퍼파라미터(Hyper Parameter)로는 지지도와 신뢰도를 선택하여 설정하게 되지만, 실제로 효용성을 파악할때는 세 가지를 모두 사용하여 평가하게 된다.
연관분석 - 규칙생성

규칙 생성 가능한 모든 경우의 수를 탐색해 지지도, 신뢰도, 향상도가 높은 규칙들을 찾아내는 방식
상품이 4개일 때 전체 경우의 수로는
4C1 + 4C2 + 4C3 + 4C4 = 15 이다.
다만 모든 경우의 수를 탐색하는 경우는 아이템이 증가함에 따라 규칙의 수가 기하급수적으로 증가해 사용하지 않고 이를 보완하기 위한 알고리즘이 Apriori 알고리즘이다.
연관분석 - Apriori 알고리즘

Apriori 알고리즘은 과도한 아이템셋의 증가를 줄여 연산량을 줄이기 위한 방법이다. 사용자가 최소 지지도를 설정하여 설정값 이하의 지지도를 갖고 있는 경우는 제거하는 방법론이다.
Apriori 알고리즘 순서
- k 개의 item을 가지고 단일항목집단 생성(one-item frequent set)
- 단일항목집단에서 최소 지지도 (support) 이상의 항목만 선택
- 2에서 선택된 항목만을 대상으로 2개항목집단 생성
- 2개항목집단에서 최소 지지도 혹은 신뢰도 이상의 항목만 선택
- 위의 과정을 k개의 k-item frequent set을 생성할때까지 반복
예를들어, 아래와 같은 구매내역 데이터(Implicit Feedback)가 존재한다.
거래 번호 상품 목록 0 우유, 기저귀, 쥬스 1 양상추, 기저귀, 맥주 2 우유, 양상추, 기저귀, 맥주 3 양상추, 맥주 위와 같은 구매 내역 데이터를 one-hot encoding과 같은 방법으로 Sparse Matrix로 변환한다.
거래번호 우유 양상추 기저귀 쥬스 맥주 0 1 0 1 1 0 1 0 1 1 0 1 2 1 1 1 0 1 3 0 1 0 0 1 5개의 item을 가지고 단일항목집단을 만들어, 최소 지지도 이상의 항목만 선택한다.(최소 지지도는 0.5로 선택)
P(우유) : 0.5
P(양상추) : 0.75
P(기저귀) : 0.75
P(쥬스) : 0.25=> 0.5 미만으로 탈락P(맥주) : 0.75
선택된 항목만을 가지고 2개항목집단 생성 {우유, 양상추, 기저귀, 맥주} 하여 2개항목집단에서 최소 지지도 이상의 항목만을 선택한다.
P({우유, 양상추}) : 0.25P({우유, 기저귀}) : 0.5
P({우유, 맥주}) : 0.25위와 같은 과정을 k개의 k-item frequent set을 생성할 때까지 반복한다.
Apriori 알고리즘 장단점
장점
- 원리가 간단해 사용자가 쉽게 이해할 수 있으며 의미를 파악 할 수 있다.
- 유의한 연관성을 갖는 구매패턴을 찾아준다.
단점
- 데이터가 클 경우 (item이 많은 경우)에 속도가 느리고 연산량이 많다.
- 실제 사용시 많은 연관상품이 나타나는 단점이 있음 - 상관관계는 알 수 있지만, 인과관계 파악은 어렵다.
import mlxtend # 연관분석을 위한 패키지 import numpy as np import pandas as pd # 데이터 셋 # 우유 기저귀 쥬스 양상추 맥주 data = np.array([ ['우유', '기저귀', '쥬스'], ['양상추', '기저귀', '맥주'], ['우유', '양상추', '기저귀', '맥주'], ['양상추', '맥주'] ])from mlxtend.preprocessing import TransactionEncoder te = TransactionEncoder() # Sparse Matrix, 인코딩 te_ary = te.fit(data).transform(data) df = pd.DataFrame(te_ary, columns=te.columns_)%%time from mlxtend.frequent_patterns import apriori apriori(df, min_support=0.5, use_colnames=True) # 최소지지도를 0.5로 설정
연관분석 - FP-Growth 알고리즘
Apriori 알고리즘의 속도측면을 FP-Tree 구조로 개선한 알고리즘이다.
FP-Growth 알고리즘 순서
- 모든 거래를 확인하여, 각 아이템마다의 지지도(support)를 계산하고 최소 지지도 이상의 아이템만 선택
- 모든 거래에서 빈도가 높은 아이템 순서대로 순서를 정렬
- 부모 노드를 중심으로 거래를 자식노드로 추가하며 tree를 생성
- 새로운 아이템이 나올 경우에는 부모노드부터 시작하고, 그렇지 않으면 기존의 노드에서 확장한다
- 위의 과정을 모든 거래에 대해 반복하여 FP-Tree를 만들고 최소 지지도 이상의 패턴만을 추출
FP-Growth 알고리즘 장단점
장점
- Apriori 알고리즘보다 빠르고 2번의 탐색만을 필요로 함
- 후보 Itemsets 을 생성할 필요없이 진행 가능
단점
- 대용량의 데이터셋에서 메모리를 효율적으로 사용하지 않음
- Apriori 알고리즘에 비해서 설계하기 어려움
- 지지도의 계산이 FP-Tree가 만들어지고 나서야 가능함
import mlxtend import numpy as np import pandas as pd data = np.array([ ['우유','기저귀','쥬스'], ['양상추','기저귀','맥주'], ['우유, '양상추', '기저귀', '맥주'], ['양상추', '맥주'] ])from mlxtend.preprocessing import TransactionEncoder te = TransactionEncoder() # Sparse Matrix, 인코딩 te_ary = te.fit(data).transform(data) df = pd.DataFrame(te_ary, columns=te.columns_)%%time from mlxtend.frequent_patterns import fpgrowth fpgrowth(df, min_supoort=0.5, use_colnames=True)
Apriori 보다 속도가 빠름 '인공지능 > RecSys(추천시스템)' 카테고리의 다른 글
[토크ON세미나/ 추천시스템 분석 입문하기] 2강 - 추천시스템의 이해 (0) 2021.12.23 - Apriori 알고리즘(2005~2010)