-
[DL Basics] 2. Optimization인공지능/부스트캠프 Ai Tech 2022. 2. 12. 09:55728x90
[DL Basics] 2. Optimization In [1]:from IPython.core.display import display, HTML display(HTML("<style>.container { width:90% !important; }</style>"))
많은 용어들을 정확히 정의하고 이해해야 타 연구자들과 커뮤니케이션에서 문제가 없다.
1-1.Generalization¶
Generlization gap : Train error와 Test error 사이의 차이
- 다만 Train error가 높은 모델에서 Generalization gap이 좋다고 좋은 모델인가? 아니지. Generalization은 train과 test의 차이를 보는것
1-2.Under-fitting vs over-fitting¶
Under-fitting은 train 데이터에 학습이 제대로 안되어 있는(모델이 너무 단순하거나..) Over-fitting은 train 데이터에 너무 학습이 잘 되어 있는(모델이 너무 복잡하거나..)
이지만 결국 train 데이터를 기준이다. 만약 target이 over-fitting 모델에 너무 잘 맞게 되면 땡 아냐..?
1-3.Cross-validation(K-fold validation)¶
NN을 학습하면서 최적화된 Hyper Paramater를 구하기 위해 validation data를 가지고 테스트 해보는 과정이다.
train data를 몇개의 조각(K-fold)로 쪼개어 최적의 Hyper Paramater를 구하면, 이를 가지고 전체 train data(많은 데이터로 학습을 위함)를 학습한 모델을 test data를 가지고 평가한다.
- valid data를 가지고 최적의 Hyper Paramater를 구하기
- 최적의 Hyper Paramater로 train 후 test를 돌린다.
중요점은 test data는 test의 경우에서만 활용해야 한다!
1-4.Bias and Variance¶
Variance : 주어진 입력을 모델에 넣었을때 출력이 얼마나 일관적으로 나오는지
- 작은 모델들은 간단한 경우가 많고, 높은 경우는 over-fitting의 위험이 높겠죠?
Bias : 내가 원하는 Target값과의 거리가 얼마나 되는지에 따라서 Bias가 높다는 건 거리가 멀다는 의미
Bias and Variance Tradeoff¶
Loss(cost)를 줄이고자 한다면, Bias, Variance, noise를 함께 줄여야 한다. 그러나 Bias와 Variance는 서로 Tradeoff 관계이기에 임계값을 찾아야 한다.
${cost}$ = ${bias^2}$ + ${variance}$ + ${noise}$
1-5.Bootstrapping¶
any test or metric that uses random sampling with replacement
학습 데이터가 100개가 있으면 100개중에서 일부분만 활용하여 여러개의 모델을 만들어 하나의 입력에 대해 각각의 모델의 결과값의 consensus(일치)를 보고 uncertainty를 보고자 할때 사용한다.
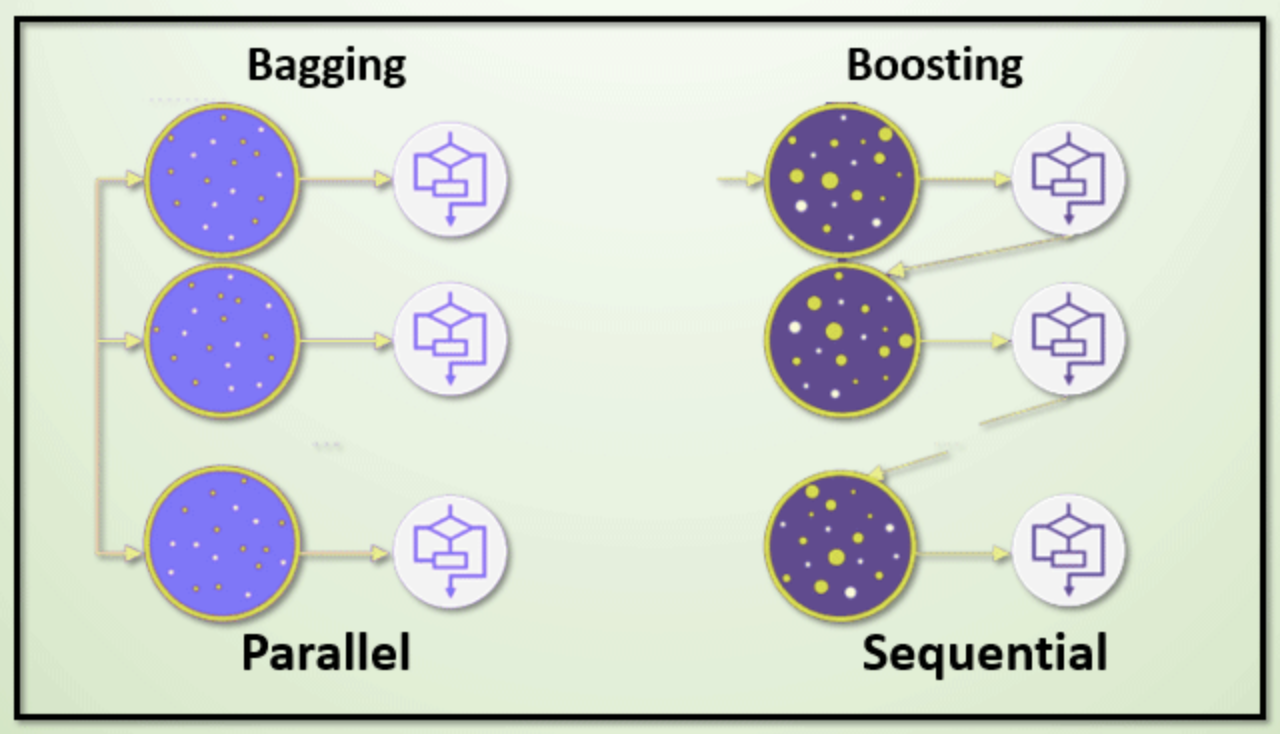
Bagging(Booststrapping aggregating)¶
Bootstrapping 방식을 활용해 나온 여러개의 모델의 결과값을 평균을 내어 결과를 정하겠다.
- 일반적으로 앙상블에서 많이 쓰임
- voting : 결과 값중에 가장 많이 선택된 것을 고른다
- averaging : 결과 값의 평균을 선택한다
Boosting¶
간단한 모델을 만들어 학습해본 뒤 100개중 20개의 데이터에 잘 동작을 하지 않는다면 20개의 데이터에 잘 동작하는 모델을 또 만든다.
- weak learners : 하나하나의 간단한 모델들
- strong model : weak learners 들을 sequence하게 하나로 모아서 weak learner들의 weight들을 잘 모아준다.
2. Practical Gradient Descent¶
Gradient Descent는 3가지로 분류 할 수 있다.
Stocahstic Gradient Descent : (엄밀한 정의) 하나의 샘플을 통해서 Gradient update
Mini-batch Gradient Descent : 하나의 Batch를 가지고 Gradient update
Batch Gradient Descent : 한번에 모든 데이터를 사용하여 모든 Gradient의 평균으로 Gradient update
대부분은 Mini-batch Gradient Descent을 활용한다.
3-1.(Stocahstic) Gradient Descent¶
${W_{t+1}}$ ${\leftarrow}$ ${W_t}$ ${- {\eta}g_t}$
${\eta}$ : Learning rate
${g_t}$ : Gradient Descent
학습이 잘되며 global Minima로 갈 수 있는 적절한 Learning rate 값을 찾는게 중요하다.
3-2.Momentum(관성)¶
${a_{t+1}}$ ${\leftarrow}$ ${{\beta}a_t}$ ${+ g_t}$
${W_{t+1}}$ ${\leftarrow}$ ${W_t}$ ${- {\eta}a_{t+1}}$
${\beta}$ : momentum
${a_{t+1}}$ : accumulation(accumulation gradient or Momentum이 포함된 gradient)
기존 방향을 이전 배치에서 향했던 방향으로 갔던 관성을 조금이라도 유지시켜보자.
3-3.Nesterov accelerated gradient(NAG)¶
${a_{t+1}}$ ${\leftarrow}$ ${{\beta}a_t}$ ${+ {\nabla}L(W_t - {\eta}{\beta}a_t)}$
${W_{t+1}}$ ${\leftarrow}$ ${W_t}$ ${- {\eta}a_{t+1}}$
${{\nabla}L(W_t - {\eta}{\beta}a_t)}$ : Lookahead gradient
gradient 계산 대신 Lookahead gradient를 계산한다. 즉 a(현재정보)가 있다면 그 방향으로 먼저 가본 후 accumulation을 계산한다.
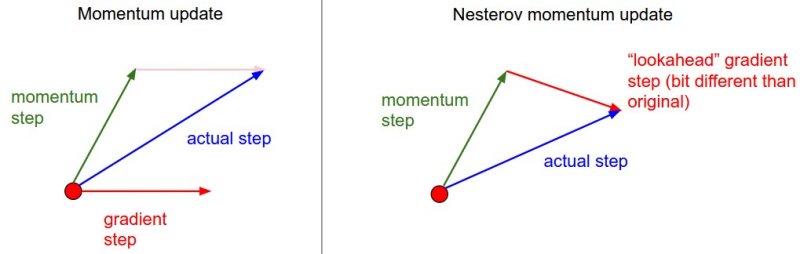
NAG는 Momentum에 비해 local minima에 더 빨리 다가갈 수 있다.
3-4.Adagrad¶
Adagrad는 adapts the learning rate, NN의 parameter가 얼마나 변했는지 안변했는지를 보겠다는 것이다.
- adaptive learning : 많이 변한 parameter에는 적게 변화를 시키고 적게 변한 parameter는 많이 변화를 시킨다.
이를 위해선 파라메터가 얼마나 변했는지 저장을 해야한다. 이를 ${G}$로 표기한다.
${W_{t+1}}$ = ${W_t - {{\eta} \over {\sqrt {G_t + \epsilon}}}g_t}$
${G_t}$ : Sum of gradent squares, 지금까지 gradient가 얼마나 변했는지 제곱해서 더한 것이다. Sum이므로 해당 값은 계속 커지게 되니 이 값을 역수로 취해서 많이 변한건 적게 적게 변한건 많이 변할 수 있게 할 수 있다.
${\epsilon}$ : for numerical stability
${\eta}$ : global learning rate
그러나 여기서 가장 큰 문제는 ${G}$는 학습이 계속 될 수록 점점 커져 나중에는 학습이 진행이 되지 않는다.
3-5.Adadelta¶
${G_t}$ = ${\gamma G_{t-1} + (1 - \gamma)g^2_t}$
${W_{t+1}}$ = ${W_t - {{\sqrt {H_{t-1}+ \epsilon}}\over {\sqrt {G_t+ \epsilon}}}g_t}$
${H_t}$ = ${\gamma H_{t-1} + (1-\gamma)(\Delta W_t)^2}$
${G_t}$ : EMA(Exponentially moving average) of gradient squares
${H_t}$ : EMA of difference squares, ${W_{t+1}}$ 의 변화값을 들고 있어서 learning rate가 없어도 된다.
현재 타임스탭 t가 주어졌을때 window size를 정해서 이전에 값들을 저장해서 ${g^2_t}$의 변화를 보겠다는 것이다. 그러나 이 경우 이전에 값들을 저장해야 하므로 메모리문제가 발생할 수 있다.
이를 해결하기 위한 방안으로 Exponentially moving average ${G_t}$로 메모리 문제를 해결 할 수 있다.
learning rate가 없다.
3-6. RMSprop¶
${G_t}$ = ${\gamma G_{t-1} + (1 - \gamma)g^2_t}$
${W_{t+1}}$ = ${W_t - {{\eta} \over {\sqrt {G_t + \epsilon}}}g_t}$
${G_t}$ : EMA of gradient squares
${\eta}$ : step-size
3-7. Adam(Adaptive Moment Estimation)¶
EMA of gradient squares와 Moment을 같이 활용한다.
${m_t}$ = ${\beta_1m_{t=1} + (1 - \beta_1)g_t}$
${v_t}$ = ${\beta_2v_{t-1} + (1 - \beta_2)g^2_t}$
${W_{t+1}}$ = ${W_t}$ - ${\eta \over {\sqrt {v_t + \epsilon}}}$ ${{\sqrt {1-\beta^t_2}\over {1- \beta^t_1}}}$ ${m_t}$
${m_t}$ : Momentum
${v_t}$ : EMA of gradient squares
4. Regularization¶
Generalization이 잘되게 하기 위함이다. 학습이 너무 잘되지 않도록 규제를 걸어 test data에서 성능이 잘 나오게 하기 위한 기능을 한다.
- Early stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Label smoothing
- Dropout
- Batch normalization
4-1. Early stopping¶
Validation error를 활용해 Training error와의 차이가 커지는 시점에서 학습을 중단시키는 기법
4-2. Parameter norm penalty¶
${total}$ ${cost}$ = ${loss(D;W) + {\alpha \over 2}\lVert W \rVert^2_2}$
NN의 paramater가 너무 커지지(크기의 관점에서 작으면 작을 수록 좋다) 않게 하는 것이다. NN가 만드는 함수의 공간속에서 최대한 부드러운 함수로 만들고자 하는것. 그래야 Generalization performance가 잘 나올 것이라고 생각하기 때문이다.
4-3. Data augmentation¶
한정적인 데이터의 숫자에서 어떻게든 변환을 하여 데이터를 늘리는 방식, 다만 변환속에서 레이블이 바뀌게 된다면 안된다.
- mnist와 같은 데이터에서는 뒤집어서 레이블이 변환되는 데이터는 고려를 해야한다.
4-4. Noise robustness¶
input 또는 weight에 Noise를 추가하는 방식
4-5. Label smoothing¶
train 단계에 있는 학습데이터 두개를 뽑아서 서로 섞어준다. 이미지 분류에 있어서 모델이 분류를 하는 decision boundary를 부드럽게 해주는 효과가 있다.
4-6. Dropout¶
학습시 일부 weight를 0으로 바꾸어 각각의 weight들이 roburst될 수 있다.
4-7. Batch normalization¶
${\mu_B}$ = ${1 \over m}$ ${\sum_{i=1}^mx_i}$
${\sigma^2_B}$ = ${1 \over m}$ ${\sum_{i=1}^m(x_i-\mu_B)^2}$
${\hat{x_i}}$ = ${x_i - \mu_B \over \sqrt{\sigma^2_B + \epsilon}}$
Batch 단위로 normalization을 한다. 간단한 분류문제를 풀때 효과적이다.

결론 : 학습이 잘 안되는건 모델이 잘못된 걸 수도 있지만, Optm도 확인해보자.
In [ ]:'인공지능 > 부스트캠프 Ai Tech' 카테고리의 다른 글
[DL Basics] 5. Modern CNN (0) 2022.02.12 [DL Basics] 4. Convolution (0) 2022.02.12 [DL Basics] 1. NN & MLP (0) 2022.02.12 [Data Viz] 2-3. Scatter Plot (0) 2022.02.04 [Data Viz] 2-2. Line Plot (0) 2022.02.04
