-
[DL Basics] 5. Modern CNN인공지능/부스트캠프 Ai Tech 2022. 2. 12. 10:01728x90
[DL Basics] 5. Modern CNN In [1]:from IPython.core.display import display, HTML display(HTML("<style>.container { width:90% !important; }</style>"))
많은 용어들을 정확히 정의하고 이해해야 타 연구자들과 커뮤니케이션에서 문제가 없다.
5. Modern CNN - 1x1 convolution의 중요성¶
- 파라미터의 숫자, 네트워크의 Depth를 중점으로 보자
네트워크의 Depth는 점점 늘어나고 숫자는 점점 줄어들며 성능은 점점 성장한다.
ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)¶
- Classification / Detection / Localization / Segmentation
- 1,000 category
5-1. AlexNet¶

- 핵심 아이디어
- ReLU(Rectified Linear Unit) activation
- GPU implementation (2 GPUs)
- Local response normalization(지금은 안중요), Overlapping pooling
- Data augmentation
- Dropout
ReLU Activation¶
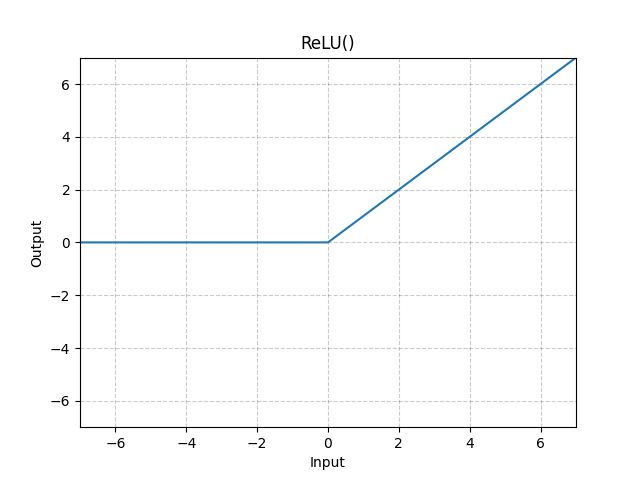
- Preserves properties of linear models : 0보다 작으면 0 아니면 그대로
- Easy to optimize with gradient descent
- Good generalization
- Overcome the vanishing gradient problem : sigmoid, tanh는 특정 구간에서 gradient가 0에 가까워지는 현상(vanishing)
5-2-1. why 3x3 convolution?¶
conv filter의 크기가 커질수록 이점은, 한번 연산될때 고려할 수 있는 input의 크기가 커진다는 이점이 있다.
- Receptive field : 하나의 convolution feature map을 얻기 위해 고려할 수 있는 input의 크기

3x3 두번과 5x5 한번은 같은 Receptive field이지만 전자가 파라미터의 갯수가 적다.
- 즉 depth를 키우고 파라미터의 숫자를 줄일 수 있다는 것
5-3. GoogLeNet¶
- NIN(network-in-network) : 비슷하게 생긴 네트워크가 계속 반복됨
inception blocks¶

inception은 하나의 Receptive field를 위해 여러개의 필터(1x1 Conv, 3x3 Conv)를 거치고 여러개의 response을 Concatenation 하는 효과가 있다.
- 1x1 Conv를 통해서 전체적인 네트워크의 파라미터 수를 줄인다.
- 1x1 Conv는 채널 방향으로 차원을 줄일 수 있다.
Benefit of 1x1 Convolution¶

1x1 Conv는 위의 이미지를 기준으로 약 30%의 파라미터 숫자를 줄일 수 있다.
5-4. ResNet¶
training과 test에서 문제가 되는 generalization gap을 Residual을 통해 해결한 Net

- identity map(skip connection) : 출력값 또는 Conv layer에 입력값을 다시 더한다. 그러므로 conv에서 학습하고자 하는 것은 f(x) + x를 하여 차이(residual)만 학습하고자 하는 것이 목적이다.

Residual을 사용하면 더 깊은 layers에서도 학습이 잘되게 해준다.
Simple/Projected Shortcut¶

- 특이한 점은 Batch Norm이 Conv 다음에 나오게 된다. 일반적으로 Simple Shortcut을 많이 쓴다.
Bottleneck architeture¶

전체적인 파라미터 숫자를 줄이기 위해 input #(Channel)을 줄이고, 3x3 Conv 다음에 #를 늘려 output #의 크기를 맞춰준다.
- input과 ouput의 #의 크기를 같게 만들어줌
Summary¶
- VGG : 3x3 blocks 반복 , 파라미터 감소
- GoogLeNet : 1x1 convolution , 파라미터 감소
- ResNet : skip-connection . 네트워크를 깊게 쌓을 수 있게
- DenseNet : concatenation , 더하는것 대신 쌓아서 성능을 좋게
In [ ]:In [ ]:'인공지능 > 부스트캠프 Ai Tech' 카테고리의 다른 글
[DL Basics] 7. Sequential Models (0) 2022.02.12 [DL Basics] 6. Computer Vision Applications (0) 2022.02.12 [DL Basics] 4. Convolution (0) 2022.02.12 [DL Basics] 2. Optimization (0) 2022.02.12 [DL Basics] 1. NN & MLP (0) 2022.02.12



